Naive Bayes
-
 Intuition :
Intuition :- Dans le cas discret : “comptage avancé”. Par exemple : étant donné une phrase x_i à classifier comme spam ou non, compter toutes les fois où chaque mot w^i_j est apparu dans des phrases spam déjà vues et prédire comme spam si le total (pondéré) des “comptes spam” est plus grand que celui des “comptes non spam”.
- Utiliser une hypothèse d’indépendance conditionnelle (“naïve”) pour obtenir de meilleures estimations des paramètres même avec peu de données.
-
 Pratique :
Pratique :- Un bon et simple point de référence.
- Performant lorsque le nombre de caractéristiques est grand, mais que la taille du jeu de données est faible.
- Complexité d’entraînement : $O(ND)$ .
- Complexité de test : $O(TDK)$ .
- Notations utilisées : \(N= \#_{train}\) ; \(K= \#_{classes}\) ; \(D= \#_{features}\) ; \(T= \#_{test}\).
-
 Avantages :
Avantages :- Simple à comprendre et à implémenter.
- Rapide et évolutif (entraînement et test).
- Gère l’apprentissage en ligne.
- Fonctionne bien avec peu de données.
- Insensible aux caractéristiques non pertinentes.
- Gère les données réelles et discrètes.
- Probabiliste.
- Gère les valeurs manquantes.
-
 Inconvénients :
Inconvénients :- Hypothèse forte d’indépendance conditionnelle des caractéristiques étant donné les étiquettes.
- Sensible aux caractéristiques rarement observées (atténué par le lissage).
</details> </div>
Naive Bayes est une famille de modèles génératifs qui prédit $p(y=c \vert\mathbf{x})$ en supposant que toutes les caractéristiques sont conditionnellement indépendantes étant donné l’étiquette : $x_i \perp x_j \vert y , \forall i,j$. Naive Bayes fait l’hypothèse que toutes les caractéristiques x_i sont conditionnellement indépendantes de $x_j$ étant donné l’étiquette y, pour tous $i,j$. Cette hypothèse de simplification est très rarement vraie en pratique, ce qui rend l’algorithme “naïf”. Classifier avec une telle hypothèse est très simple :
\[\begin{aligned} \hat{y} &= arg\max_c p(y=c\vert\mathbf{x}, \pmb\theta) \\ &= arg\max_c \frac{p(y=c, \pmb\theta)p(\mathbf{x}\vert y=c, \pmb\theta) }{p(x, \pmb\theta)} & & \text{Règle Bayes} \\ &= arg\max_c \frac{p(y=c, \pmb\theta)\prod_{j=1}^D p(x_j\vert y=c, \pmb\theta) }{p(x, \pmb\theta)} & & \text{Hypothèse d'indépendance conditionnelle} \\ &= arg\max_c p(y=c, \pmb\theta)\prod_{j=1}^D p(x_j\vert y=c, \pmb\theta) & & \text{Dénominateur constant} \end{aligned}\]Notez que, comme nous sommes dans un cadre de classification, $y$ prend des valeurs discrètes, donc $p(y=c, \pmb\theta)=\pi_c$ est une distribution catégorielle.
Vous vous demandez peut-être pourquoi nous utilisons l'hypothèse de simplification de l'indépendance conditionnelle. Nous pourrions prédire directement en utilisant $\hat{y} = arg\max_c p(y=c, \pmb\theta)p(\mathbf{x} \vert y=c, \pmb\theta)$. L’hypothèse conditionnelle nous permet d’obtenir de meilleures estimations des paramètres $\pmb{\theta}$ en utilisant moins de données . En effet,$p(\mathbf{x} \vert y=c, \pmb\theta)$ nécessite beaucoup plus de données puisqu’il s’agit d’une distribution de dimension $D$ (pour chaque étiquette possible c), tandis que $\prod_{j=1}^D p(x_j \vert y=c, \pmb\theta)$ la factorise en $D$ distributions unidimensionnelles, nécessitant beaucoup moins de données à ajuster en raison de la malédiction de la dimensionnalité. En plus de nécessiter moins de données, cela permet également de mélanger facilement différentes familles de distributions pour chaque caractéristique.
Nous devons encore répondre à deux questions importantes :
- Quelle famille de distributions utiliser pour $p(x_j \vert y=c, \pmb\theta)$ (souvent appelée modèle d’événement du classificateur Naive Bayes) ?
- Comment estimer les paramètres $\theta$?
Modèles d’événements du Naive Bayes
La famille de distributions à utiliser est un choix de conception important qui donnera lieu à des types spécifiques de classificateurs Naive Bayes. Il est important de noter que la famille de distributions $p(x_j \vert y=c, \pmb\theta)$ n’a pas besoin d’être la même pour tous les $j$, ce qui permet d’utiliser des caractéristiques très différentes (exemple : des données continues et discrètes). En pratique, on utilise souvent la distribution Gaussienne pour les caractéristiques continues, et les distributions Multinomiale ou Bernoulli pour les caractéristiques discrètes :
Naive Bayes Gaussien :
Utiliser une distribution Gaussienne est une hypothèse typique lorsqu’on traite des données continues $x_j \in \mathbb{R}$. Cela revient à supposer que chaque caractéristique, conditionnée par l’étiquette, suit une distribution Gaussienne univariée :
\[p(x_j \vert y=c, \pmb\theta) = \mathcal{N}(x_j;\mu_{jc},\sigma_{jc}^2)\]Notez que si toutes les caractéristiques sont supposées gaussiennes, cela correspond à ajuster une distribution Gaussienne multivariée avec une covariance diagonale : $p(\mathbf{x} \vert y=c, \pmb\theta)= \mathcal{N}(\mathbf{x};\pmb\mu_{c},\text{diag}(\pmb\sigma_{c}^2))$.
La limite de décision est quadratique car elle correspond aux ellipses (gaussiens) qui interceptent .
Naive Bayes Multinomial :
Dans le cas des caractéristiques catégoriques $x_j \in \{1,…, K\}$ on peut utiliser une distribution Multinomiale, où $\theta_{jc}$ représente la probabilité d’avoir la caractéristique $j$ à n’importe quel moment pour un exemple de classe $c$ :
\[p(\pmb{x} \vert y=c, \pmb\theta) = \operatorname{Mu}(\pmb{x}; \theta_{jc}) = \frac{(\sum_j x_j)!}{\prod_j x_j !} \prod_{j=1}^D \theta_{jc}^{x_j}\]Naive Bayes Multinomial est généralement utilisé pour la classification de documents, et correspond à la représentation de tous les documents sous forme de sac de mots (sans ordre). On estime alors $\theta_{jc}$ en comptant les occurrences des mots pour déterminer les proportions de fois où le mot $j$ apparaît dans un document classé comme $c$.
L’équation ci-dessus est appelée Naive Bayes bien que les caractéristiques $x_j$ ne soient techniquement pas indépendantes en raison de la contrainte $\sum_j x_j = const$. La procédure de formation est toujours la même parce que pour la classification, nous ne nous soucions que de comparer les probabilités plutôt que leurs valeurs absolues, auquel cas Multinomial Naive Bayes donne en fait les mêmes résultats qu'un produit de Categoryical Naive Bayes dont les caractéristiques satisfont la propriété de l'indépendance conditionnelle.
Naive Bayes Multinomial est un classificateur linéaire lorsqu’il est exprimé en espace logarithmique :
\[\begin{aligned} \log p(y=c \vert \mathbf{x}, \pmb\theta) &\propto \log \left( p(y=c, \pmb\theta)\prod_{j=1}^D p(x_j \vert y=c, \pmb\theta) \right)\\ &= \log p(y=c, \pmb\theta) + \sum_{j=1}^D x_j \log \theta_{jc} \\ &= b + \mathbf{w}^T_c \mathbf{x} \\ \end{aligned}\]Naive Bayes Bernoulli Multivarié :
Dans le cas des caractéristiques binaires $x_j \in \{0,1\}$ on peut utiliser une distribution Bernoulli, où $\theta_{jc}$ représente la probabilité que la caractéristique $j apparaisse dans la classe c$:
\[p(x_j \vert y=c, \pmb\theta) = \operatorname{Ber}(x_j; \theta_{jc}) = \theta_{jc}^{x_j} \cdot (1-\theta_{jc})^{1-x_j}\]Le Naive Bayes Bernoulli est typiquement utilisé pour classer des textes courts, et correspond à l’examen de la présence et de l’absence de mots dans une phrase (sans tenir compte des comptes).
Le Naive Bayes Bernoulli multivarié n’est pas équivalent à l’utilisation du Naive Bayes Multinomial avec des comptes de fréquence tronqués à 1 .En effet, il modélise à la fois l’absence et la présence des mots.
Entraînement
Enfin, nous devons entraîner le modèle en trouvant les meilleurs paramètres estimés $\hat\theta$. Cela peut être fait soit en utilisant des estimations ponctuelles (par exemple MLE), soit avec une perspective bayésienne.
Estimation du Maximum de Vraisemblance (MLE) :
La log-vraisemblance négative du jeu de données $\mathcal{D}=\{\mathbf{x}^{(n)},y^{(n)}\}_{n=1}^N$ est :
\[\begin{aligned} NL\mathcal{L}(\pmb{\theta} \vert \mathcal{D}) &= - \log \mathcal{L}(\pmb{\theta} \vert \mathcal{D}) \\ &= - \log \prod_{n=1}^N \mathcal{L}(\pmb{\theta} \vert \mathbf{x}^{(n)},y^{(n)}) & & \textit{i.i.d} \text{ dataset} \\ &= - \log \prod_{n=1}^N p(\mathbf{x}^{(n)},y^{(n)} \vert \pmb{\theta}) \\ &= - \log \prod_{n=1}^N \left( p(y^{(n)} \vert \pmb{\pi}) \prod_{j=1}^D p(x_{j}^{(n)} \vert\pmb{\theta}_j) \right) \\ &= - \log \prod_{n=1}^N \left( \prod_{c=1}^C \pi_c^{\mathcal{I}[y^{(n)}=c]} \prod_{j=1}^D \prod_{c=1}^C p(x_{j}^{(n)} \vert \theta_{jc})^{\mathcal{I}[y^{(n)}=c]} \right) \\ &= - \log \left( \prod_{c=1}^C \pi_c^{N_c} \prod_{j=1}^D \prod_{c=1}^C \prod_{n : y^{(n)}=c} p(x_{j}^{(n)} \vert \theta_{jc}) \right) \\ &= - \sum_{c=1}^C N_c \log \pi_c + \sum_{j=1}^D \sum_{c=1}^C \sum_{n : y^{(n)}=c} \log p(x_{j}^{(n)} \vert \theta_{jc}) \\ \end{aligned}\]Comme la log-vraisemblance négative se décompose en termes qui dépendent uniquement de $\pi$ et de chaque $\theta_{jc}$, nous pouvons optimiser tous les paramètres séparément.
En minimisant le premier terme en utilisant des multiplicateurs de Lagrange pour imposer $\sum_c \pi_c$, , nous obtenons que $\hat\pi_c = \frac{N_c}{N}$. qui est naturellement la proportion d’exemples étiquetés avec $y=c$.
La valeur de $\theta{jc}$ dépend de la famille de distribution que nous utilisons. Dans le cas du Multinomial, on peut montrer que $\hat\theta{jc}=\frac{N_{jc}}{N_c}$. Ce qui est très simple à calculer, car il suffit de compter le nombre de fois qu’une certaine caractéristique $x_j$ est observée dans un exemple avec l’étiquette $y=c$.
Estimation Bayésienne :
Le problème avec l’estimation du maximum de vraisemblance (MLE) est qu’elle conduit souvent à du sur-apprentissage (overfitting). Par exemple, si une caractéristique est toujours présente dans tous les échantillons d’entraînement (par exemple le mot “the” dans la classification de documents), alors le modèle échouera s’il voit un échantillon de test sans cette caractéristique, car il attribuera une probabilité de 0 à toutes les étiquettes.
En adoptant une approche bayésienne, le sur-apprentissage est atténué grâce aux a priori. Pour ce faire, nous devons calculer l’apostériori :
\[\begin{aligned} p(\pmb\theta \vert \mathcal{D}) &= \prod_{n=1}^N p(\pmb\theta \vert \mathbf{x}^{(n)},y^{(n)}) & \textit{i.i.d} \text{ dataset} \\ &\propto \prod_{n=1}^N p(\mathbf{x}^{(n)},y^{(n)} \vert \pmb\theta)p(\pmb\theta) \\ &\propto \prod_{c=1}^C \left( \pi_c^{N_c} \cdot p(\pi_c) \right) \prod_{j=1}^D \prod_{c=1}^C \prod_{n : y^{(n)}=c} \left( p(x_{j}^{(n)} \vert \theta_{jc}) \cdot p(\theta_{jc}) \right) \\ \end{aligned}\]Using (factored) conjugate priors (Dirichlet for Multinomial, Beta for Bernoulli, Gaussian for Gaussian), this gives the same estimates as in the MLE case (the prior has the same form than the likelihood and posterior) but regularized.
The Bayesian framework requires predicting by integrating out all the parameters $\pmb\theta$. The only difference with the first set of equations we have derived for classifying using Naive Bayes, is that the predictive distribution is conditioned on the training data $\mathcal{D}$ instead of the parameters $\pmb\theta$:
\[\begin{aligned} \hat{y} &= arg\max_c p(y=c \vert \pmb{x},\mathcal{D}) \\ &= arg\max_c \int p(y=c\vert \pmb{x},\pmb\theta) p(\pmb\theta \vert \mathcal{D}) d\pmb\theta\\ &= arg\max_c \int p(\pmb\theta\vert\mathcal{D}) p(y=c \vert\pmb\theta) \prod_{j=1}^D p(x_j\vert y=c, \pmb\theta) d\pmb\theta \\ &= arg\max_c \left( \int p(y=c\vert\pmb\pi) p(\pmb\pi \vert \mathcal{D}) d\pmb\pi \right) \prod_{j=1}^D \int p(x_j\vert y=c, \theta_{jc}) p(\theta_{jc}\vert\mathcal{D}) d\theta_{jc} & & \text{Factored prior} \\ \end{aligned}\]Comme auparavant, le terme à maximiser se décompose en un terme par paramètre. Tous les paramètres peuvent donc être maximisés indépendamment. Ces intégrales sont généralement intraitables, mais dans le cas des distributions Gaussienne, Multinomiale et Bernoulli avec leurs a priori conjugués correspondants, nous pouvons heureusement calculer une solution sous forme fermée.
Dans le cas du Multinomial (et du Bernoulli), la solution est équivalente à la prédiction avec une estimation ponctuelle $\hat{\pmb\theta}=\bar{\pmb\theta}$. Où $\bar{\pmb\theta}$ est la moyenne de la distribution postérieure
En utilisant un a priori symétrique de Dirichlet : $p(\pmb\pi)=\text{Dir}(\pmb\pi; \pmb{1}\alpha_\pi)$ , nous obtenons que $\hat\pi_c = \bar\pi_c = \frac{N_c + \alpha_\pi }{N + \alpha_\pi C}$.
Le Naive Bayes bayésien Multinomial est équivalent à prédire avec une estimation ponctuelle :
\[\bar\theta_{jc} = \hat\theta_{jc}=\frac{N_{jc} + \alpha }{N_c + \alpha D}\]I.e. C’est-à-dire que le Naive Bayes bayésien Multinomial avec un a priori symétrique de Dirichlet assigne une distribution postérieure prédictive :
\[p(y=c\vert\mathbf{x},\mathcal{D}) \propto \frac{N_c + \alpha_\theta }{N + \alpha_\theta C} \prod_{j=1}^D \frac{N_{jc} + \alpha_\theta }{N_c + \alpha_\theta D}\]Le modèle graphique correspondant est :
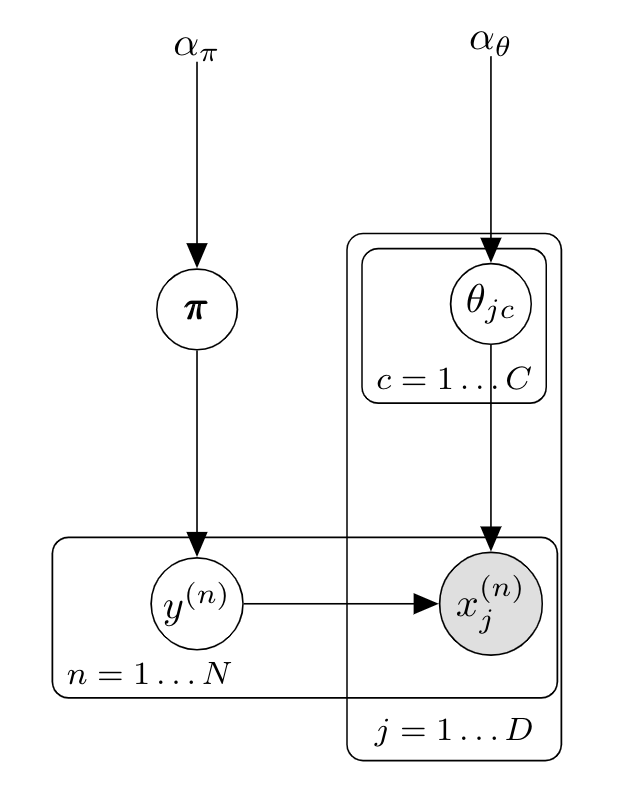
Lorsque l’on utilise un a priori uniforme $\alpha_\theta=1$, cette équation est appelée lissage de Laplace ou lissage additif d’unité. $\alpha$ représente intuitivement un “pseudo-compte” $\alpha_\theta$ pour les caractéristiques $x_{jc}$ . Pour la classification de documents , cela correspond simplement à attribuer un compte initial non nul à tous les mots, ce qui évite le problème de trouver un document de test $x^{(t)}$ with $p(y=c\vert x^{(t)})=0$ s’il contient un seul mot $x_{j}^*$ qui n’a jamais été vu dans un document d’entraînement avec l’étiquette $c$. $\alpha=1$ est un choix commun dans les exemples bien que des valeurs plus petites fonctionnent souvent mieux.
![]() Remarques :
Remarques :
Le terme “Naive” provient de l’indépendance conditionnelle des caractéristiques étant donné l’étiquette. La partie “Bayes” du nom provient de l’utilisation du théorème de Bayes pour utiliser un modèle génératif, mais il ne s’agit pas d’une méthode bayésienne puisqu’il n’est pas nécessaire de marginaliser sur tous les paramètres.
Si nous estimions le Naive Bayes Multinomial en utilisant une estimation a posteriori maximale (MAP) au lieu de la MSE ou de la méthode bayésienne, nous prédirions en utilisant le mode de l’apostériori (au lieu de la moyenne dans le cas bayésien) $\hat\theta_{jc}=\frac{N_{jc} + \alpha - 1}{N_c + (\alpha -1)D}$ (de même pour $\pmb\pi$). Cela signifie que le lissage de Laplace peut également être interprété comme l’utilisation de MAP avec un a priori non uniforme $\text{Dir}(\pmb\theta; \pmb{2})$. Mais lorsque l’on utilise un a priori uniforme de Dirichlet, MAP coïncide avec la MSE.
Le Naive Bayes Gaussien est équivalent à l’analyse discriminante quadratique lorsque chaque matrice de covariance $\Sigma_c$ est diagonale.
Le Naive Bayes discret et la régression logistique forment une “paire génératif-discriminatif”, car ils prennent tous deux la même forme (linéaire en probabilités logarithmiques) mais estiment les paramètres différemment. Par exemple, dans le cas binaire, Naive Bayes prédit la classe avec la probabilité la plus élevée. C’est-à-dire qu’il prédit $C_1$ si $\log \frac{p(C_1 \vert \pmb{x})}{p(C_2 \vert \pmb{x})} = \log \frac{p(C_1 \vert \pmb{x})}{1-p(C_1 \vert \pmb{x})} > 0$. Nous avons vu que le Naive Bayes discret est linéaire dans l’espace logarithmique, donc nous pouvons réécrire l’équation comme $\log \frac{p(C_1 \vert \pmb{x})}{1-p(C_1 \vert \pmb{x})} = 2 \log p(C_1 \vert \pmb{x}) - 1 = 2 \left( b + \mathbf{w}^T_c \mathbf{x} \right) - 1 = b' + \mathbf{w'}^T_c \mathbf{x} > 0$. Cette régression linéaire sur le ratio de cotes logarithmique correspond exactement à la forme de la régression logistique (l’équation habituelle est récupérée en résolvant $\log \frac{p}{1-p} = b + \mathbf{w'}^T \mathbf{x}$). On peut montrer la même chose pour Naive Bayes Multinomial et la régression logistique multinomiale.
Pour la classification de documents, il est courant de remplacer les comptes bruts dans le Naive Bayes Multinomial par des poids tf-idf .
![]() Ressources : Voir la section 3.5 du K. Murphy's book pour toutes les étapes de dérivation et les exemples.
Ressources : Voir la section 3.5 du K. Murphy's book pour toutes les étapes de dérivation et les exemples.